# 开始使用
这里要给大家做示例的网站是 中国政府网要闻频道 (opens new window) ,网址:http://www.gov.cn/xinwen/yaowen.htm (opens new window),我们将通过采集中国政府网的新闻列表来说明如何快速采集 Web 页面。
# 建立采集规则
进入 SSCMS 管理后台,点击左侧- 信息采集 -> 添加采集规则,进入采集规则添加界面,我们可以发现建立采集规则一共需要进行基本属性、采集网址、标题及正文、可选字段、其他选填项五个步骤:

我们先设置 基本属性:
# 基本属性
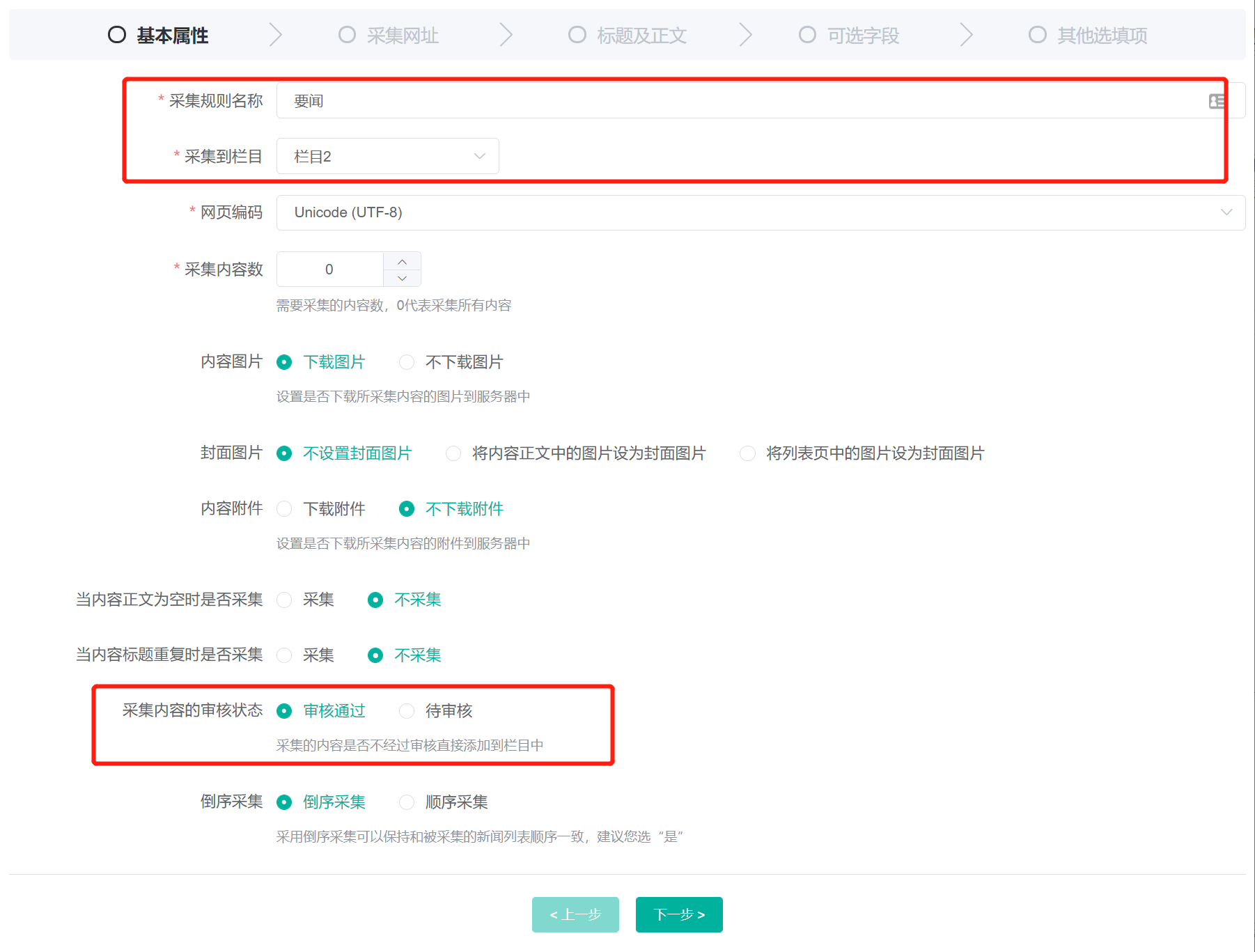
采集规则名称可以任意填写,例如我们设置为:要闻;采集到栏目为必填项,我们选择当前站点下的新闻资讯频道;采集内容的审核状态我们设置为审核通过,让采集下来的内容可以直接显示到网站中;
其他设置我们采用默认值,点击下一步,进入 采集网址 设置界面:
# 采集网址
采集网址部分需要我们填写列表页面地址以及列表页 HTML 代码中详情页链接的开始及结束代码。
我们在浏览器访问列表页 (opens new window),右键选择 查看网页源代码 获取到列表页的 HTML 代码,在代码中找到详情页的地址,然后获取前面和后面的代码,拷贝到列表页内容地址开始及列表页内容地址结束文本框中。
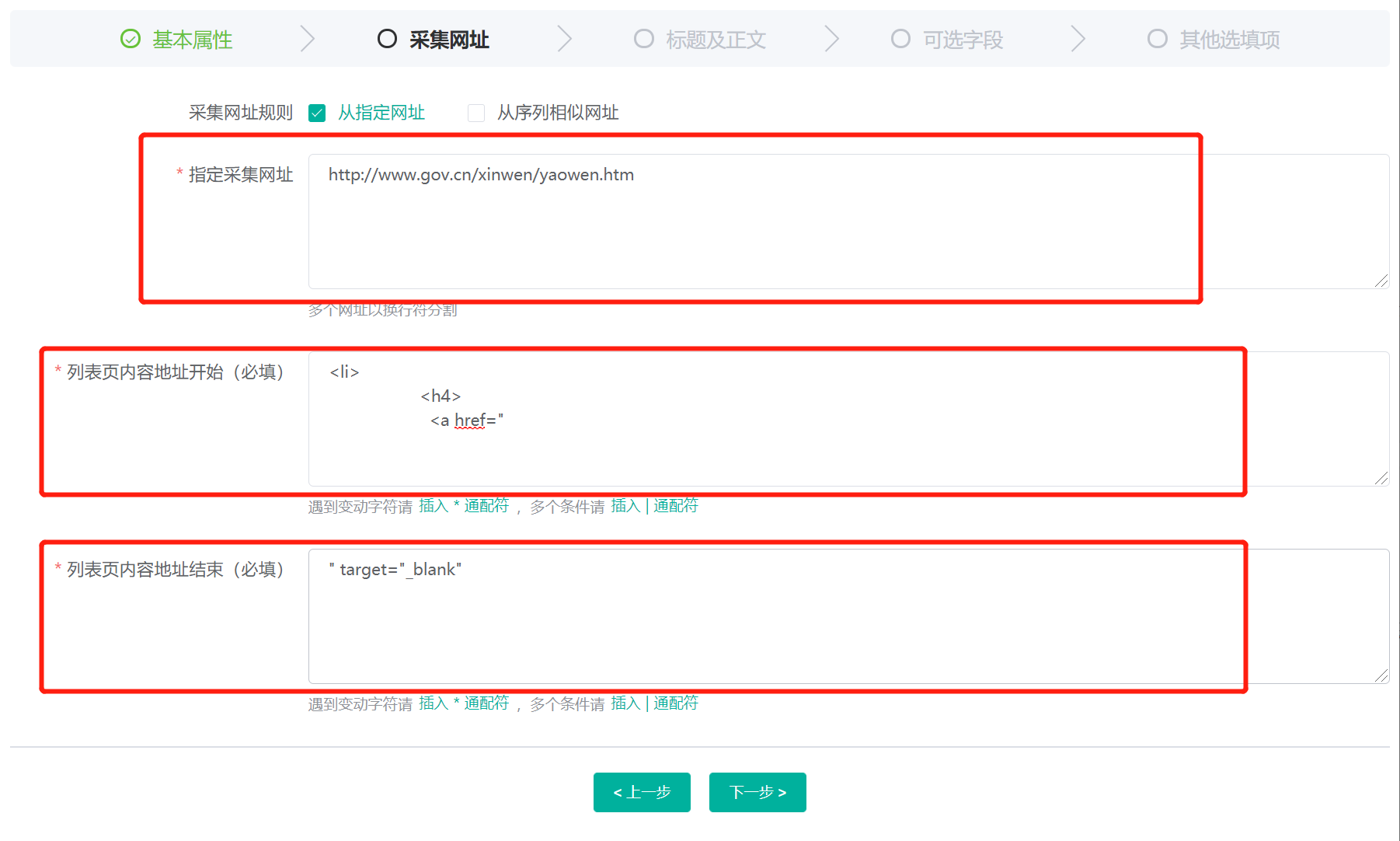
指定采集网址为需要采集的列表页面地址,在此我们设置为:
http://www.gov.cn/xinwen/yaowen.htm
列表页内容地址开始(必填)为需要采集的列表页面 HTML 代码中详情页链接前面的代码,在此我们设置为:
<li>
<h4>
<a href="
列表页内容地址结束(必填)为需要采集的列表页面 HTML 代码中详情页链接后面的代码,在此我们设置为:
" target="_blank"
点击下一步,进入 标题及正文 设置界面:
# 标题及正文
标题及正文部分需要我们填写内容页 HTML 代码中标题的开始及结束代码(不包含标题本身)以及正文的开始及结束代码(不包含正文本身),我们点击任意一篇内容页面,在浏览器中右键选择 查看网页源代码 获取到内容页面的 HTML 代码,在代码中找到标题及正文,然后获取前面和后面的代码,拷贝到标题及正文文本框中。
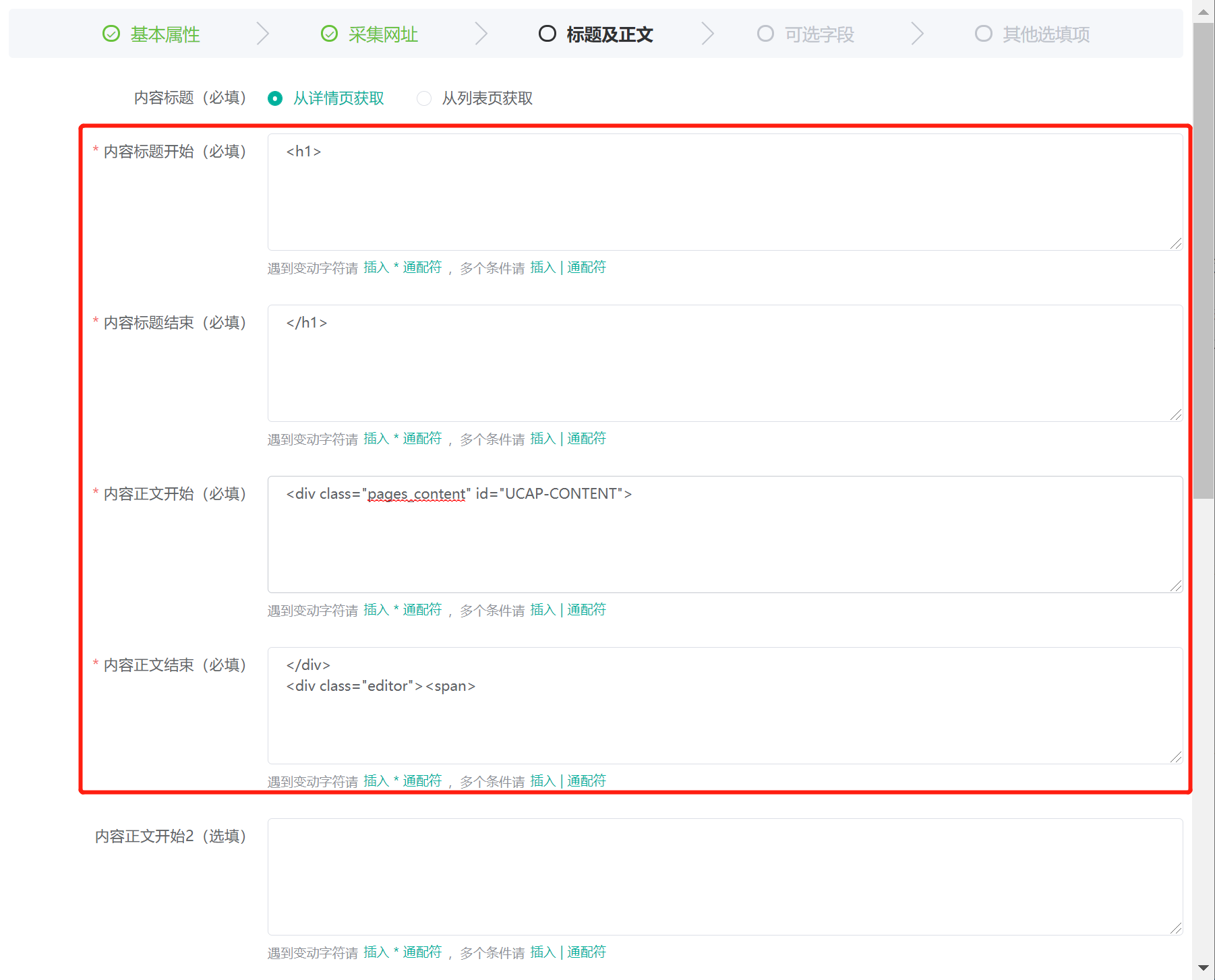
内容标题开始(必填)为需要采集的内容页面 HTML 代码中标题前面的代码,在此我们设置为:<h1>内容标题结束(必填)为需要采集的内容页面 HTML 代码中标题后面的代码,在此我们设置为:</h1>内容正文开始(必填)为需要采集的内容页面 HTML 代码中正文前面的代码,在此我们设置为:<div class="pages_content" id="UCAP-CONTENT">内容正文结束(必填)为需要采集的内容页面 HTML 代码中正文后面的代码,在此我们设置为:</div> <div class="editor"><span>
其他填写项我们留空即可,点击下一步,进入 可选字段 设置界面:
# 可选字段
我们可以在可选字段界面中采集除标题和正文之外的字段,例如我们希望获取内容添加日期的值,我们可以在浏览器中打开内容页面,右键选择 查看网页源代码 获取到内容页面的 HTML 代码,在代码中找到添加日期,然后获取前面和后面的代码。
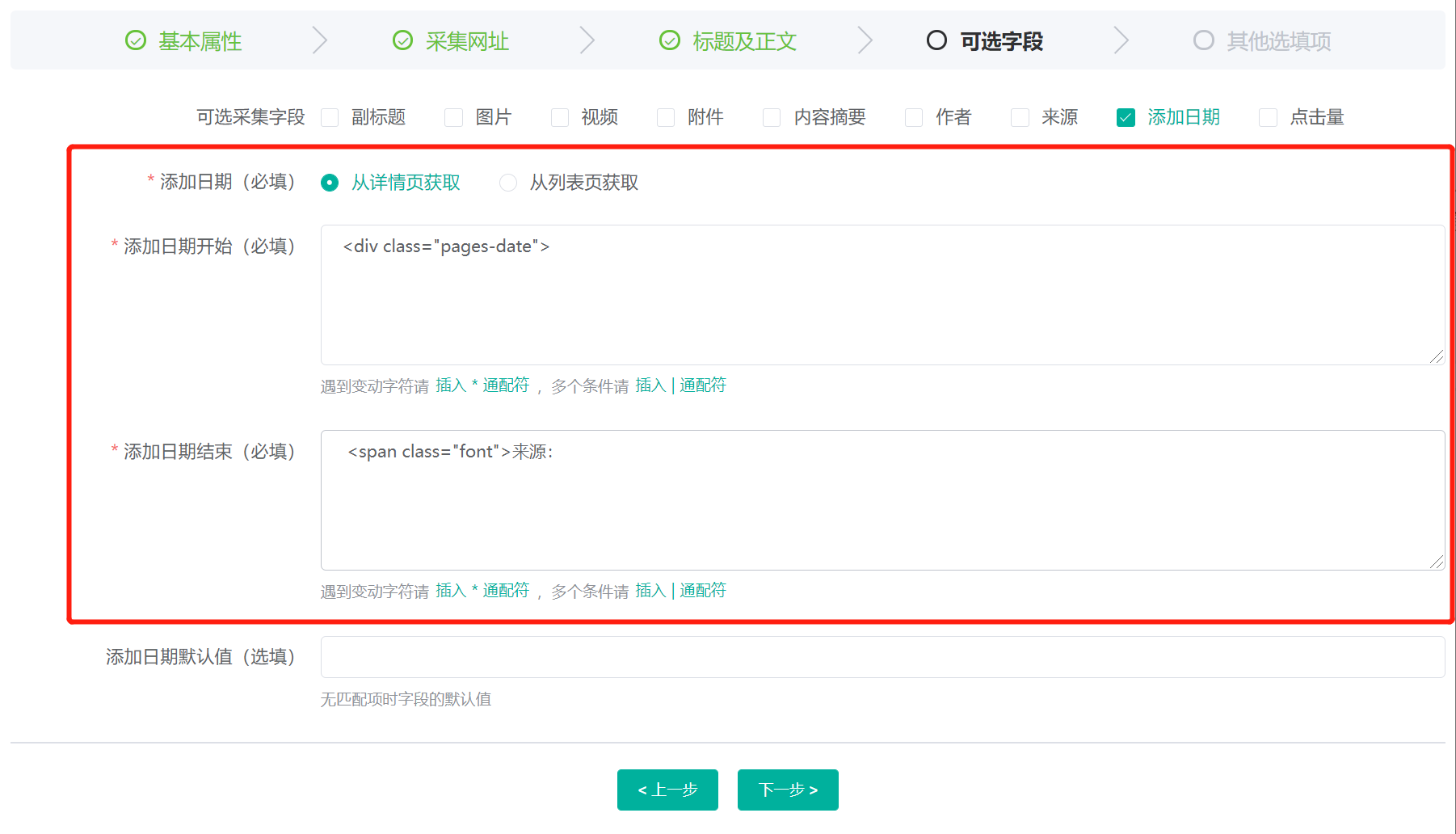
可选采集字段为需要采集的额外字段,在此,我们勾选添加日期添加日期(必填)为添加日期的代码源,在此,我们选择从详情页获取添加日期开始(必填)为需要采集的内容页面 HTML 代码中标题前面的代码,在此我们设置为:<div class="pages-date">添加日期结束(必填)为需要采集的内容页面 HTML 代码中标题后面的代码,在此我们设置为:<span class="font">来源:
点击下一步,进入 其他选填项 设置界面:
# 其他选填项
我们可以在其他选填项界面中设置采集的各种控制选项,在此我们不做修改。
点击下一步,系统将提示成功信息:

# 测试采集规则
添加完毕采集规则后,我们进入 信息采集 -> 采集规则管理 菜单,可以看到之前添加的采集规则:
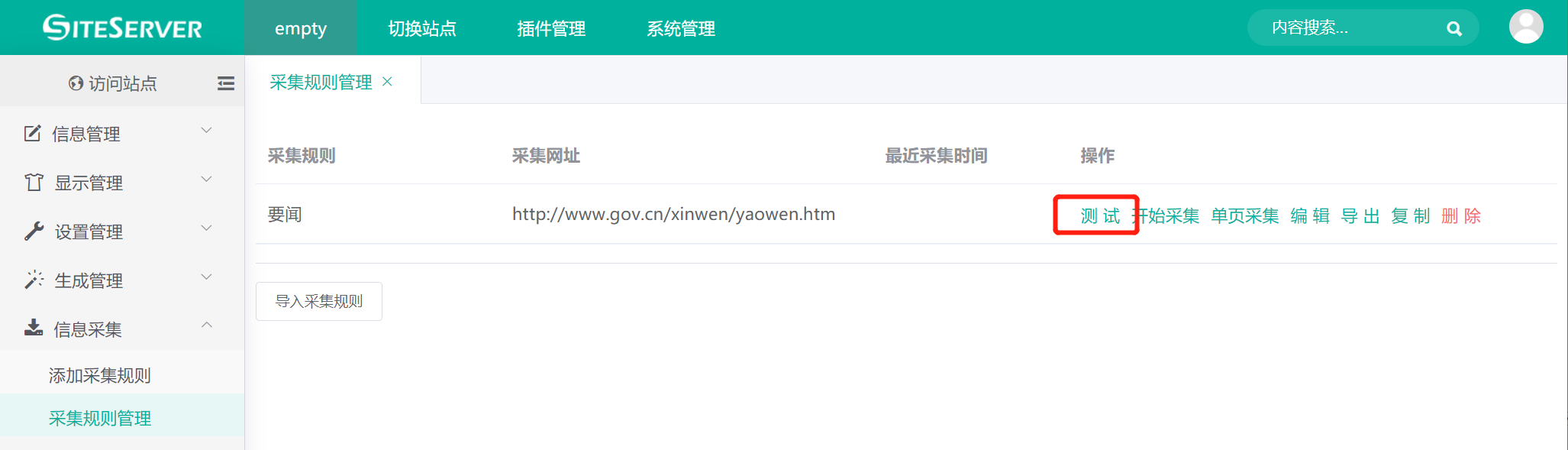
点击界面中的 测试 链接,进入测试采集规则界面,点击 获取内容链接 按钮,获取列表页包含的内容链接:
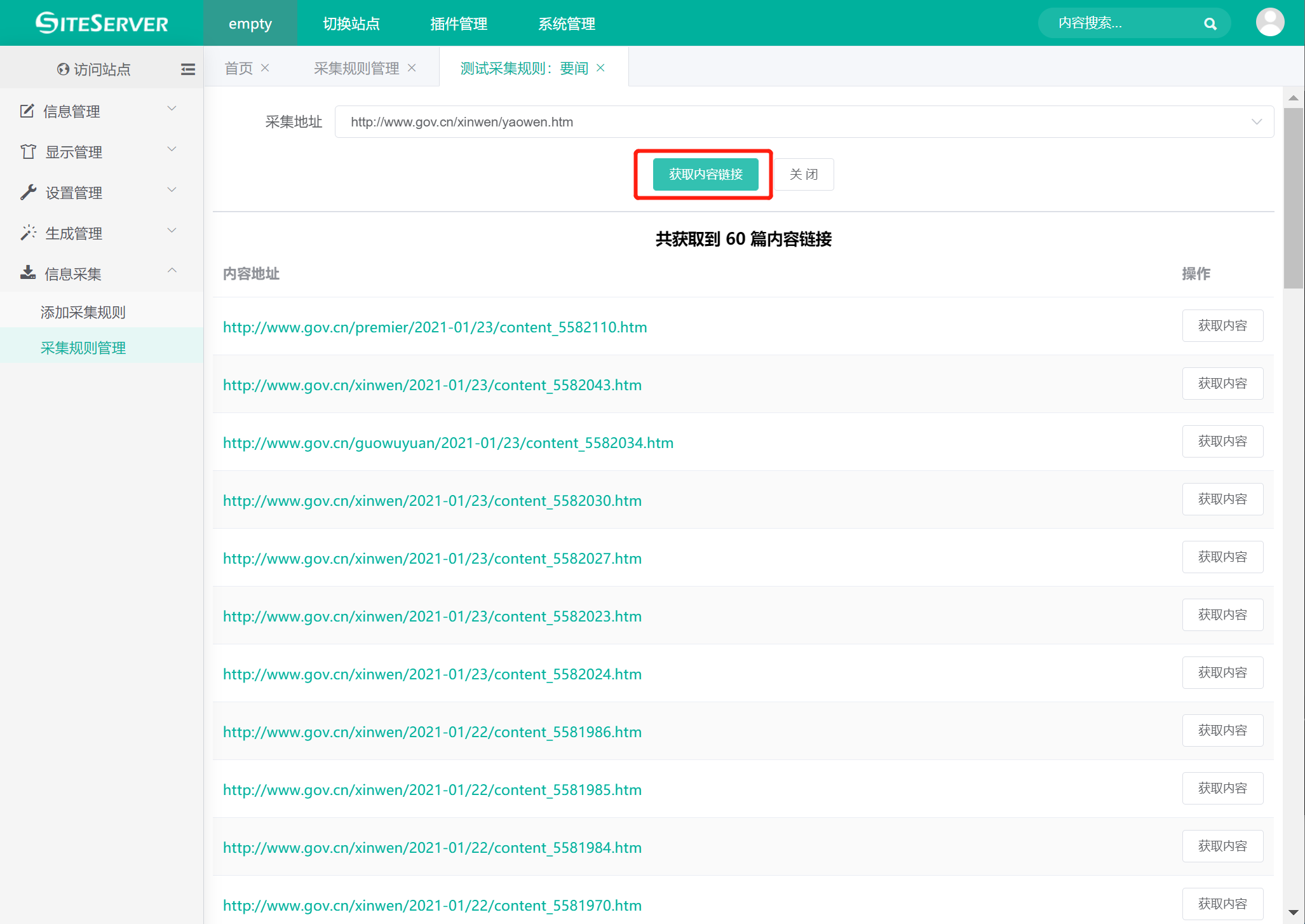
可以看到系统共获取到60篇内容,证明采集地址规则无误。
接下来点击具体内容右侧的 获取内容 按钮,系统将弹出获取内容界面:
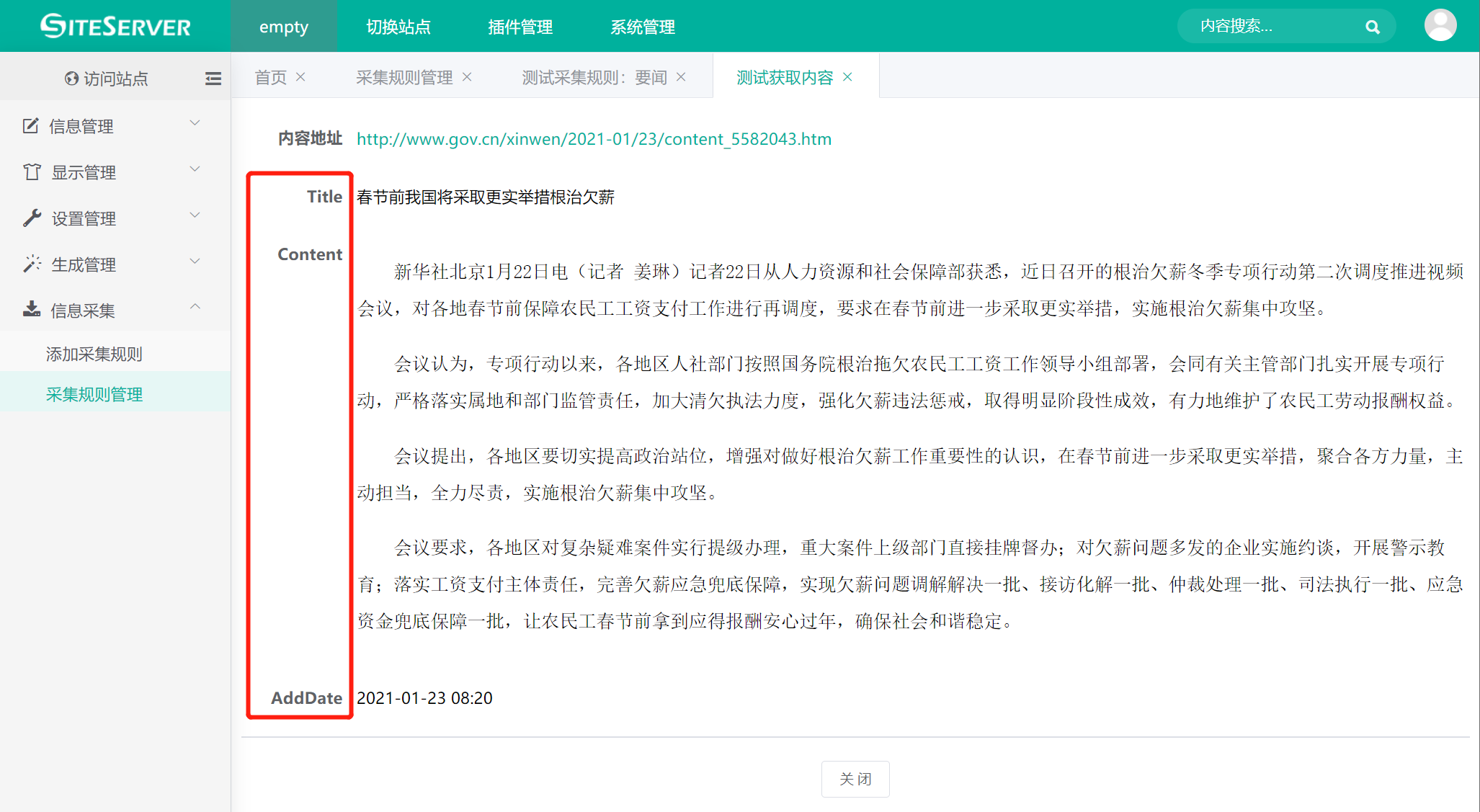
可以看到,采集插件正确获取了包含标题(title)、正文(Content)和添加时间(AddDate)的值,证明采集内容规则无误。
测试通过后,我们就可以开始正式将数据采集到站点中了。
# 开始采集
我们进入 信息采集 -> 采集规则管理 菜单,找到对应的采集规则:
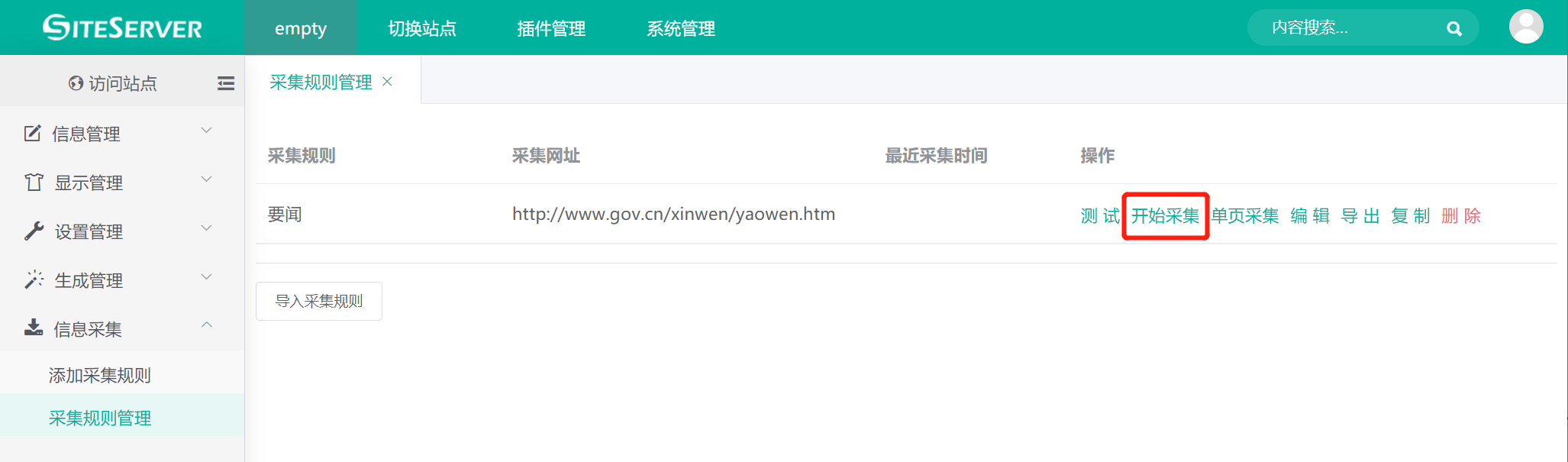
点击 开始采集 链接,系统将出现采集确认界面,如下图:
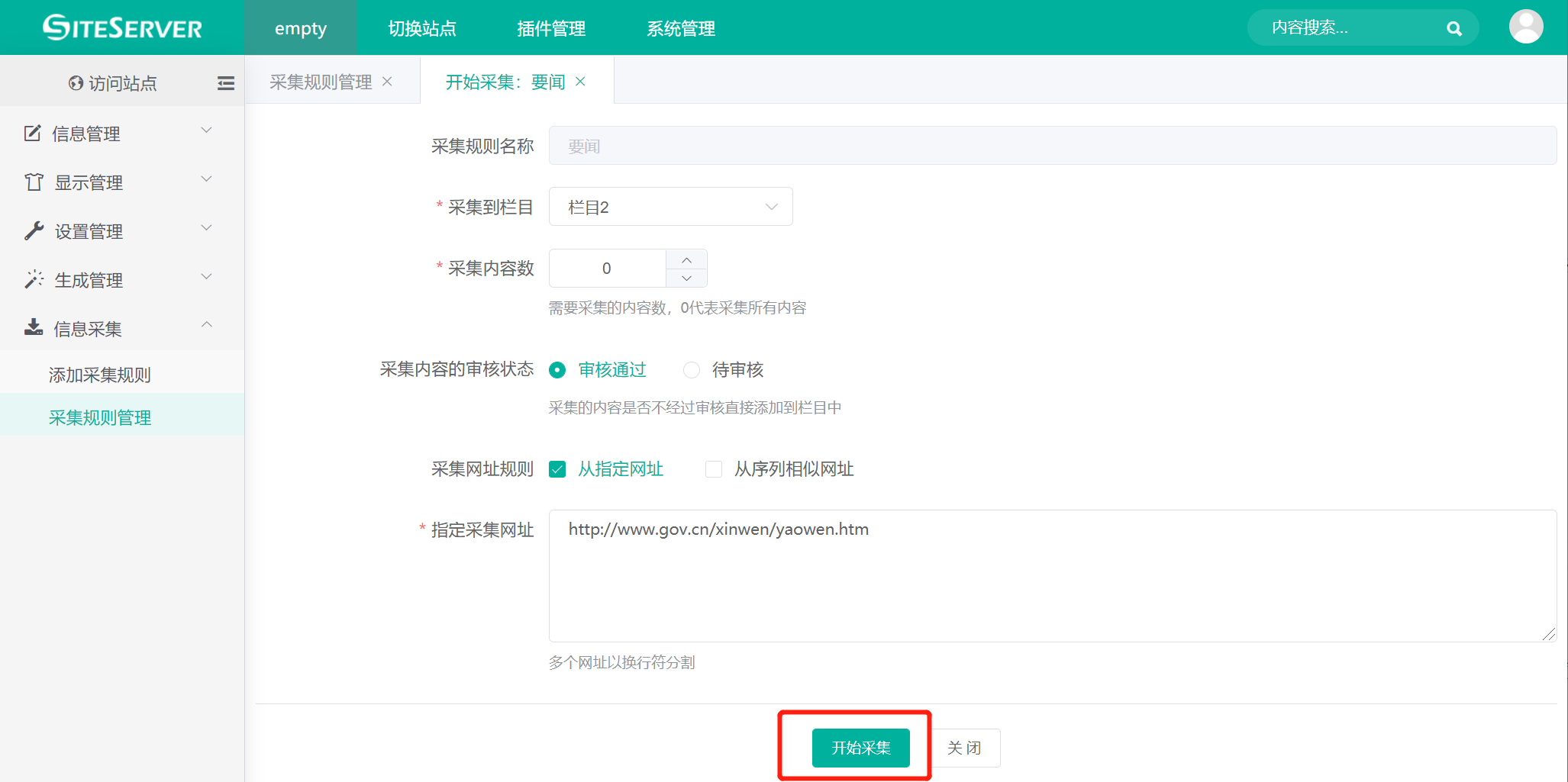
采集确认界面会列出可能需要修改的参数选项,如果没有需要修改的选项,点击 开始采集 按钮,进入采集进度界面:
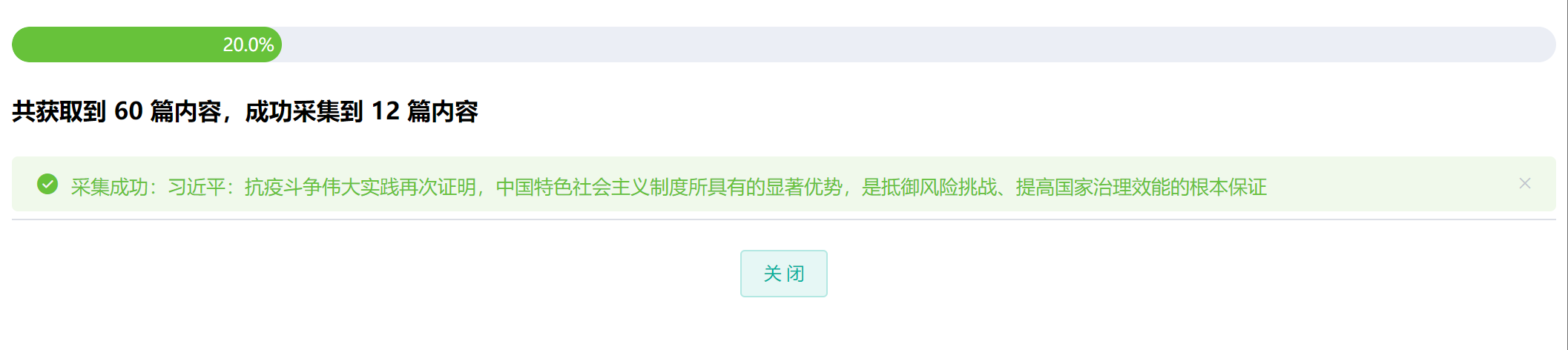
等待采集结束后,采集进度界面将显示成功采集的数量。
如果存在例外页面,采集插件可能无法采集对应的内容页,采集进度界面将显示采集失败的页面地址,方便查询原因。
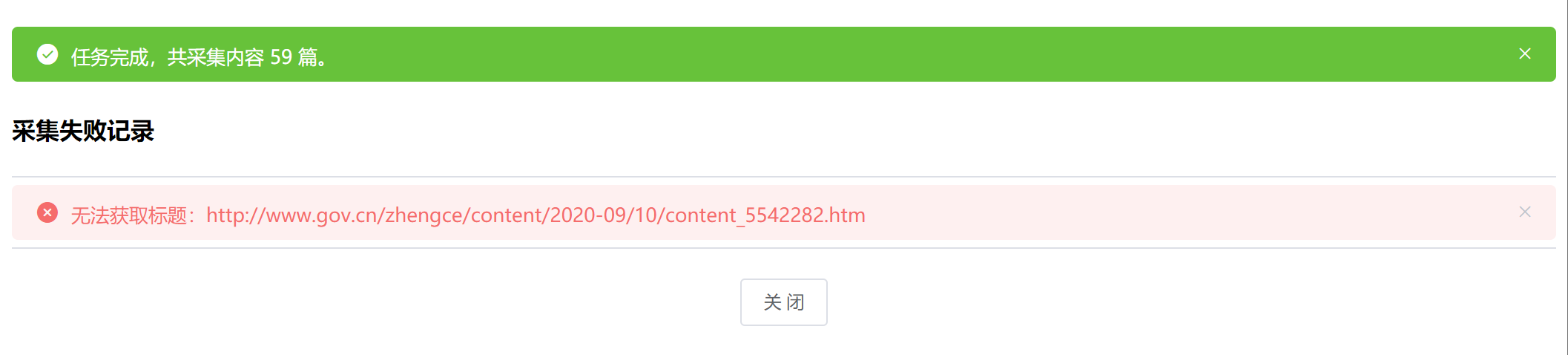
本例中有一篇内容采集失败,原因为最终内容为信息公开页面,而非普通的新闻页面(可以进一步修改规则,以包含信息公开页面)。
至此,中国政府网要闻频道采集完毕。