# 基本属性
采集规则基本属性包括采集规则的名称、以及其他的采集参数设置,如下图:
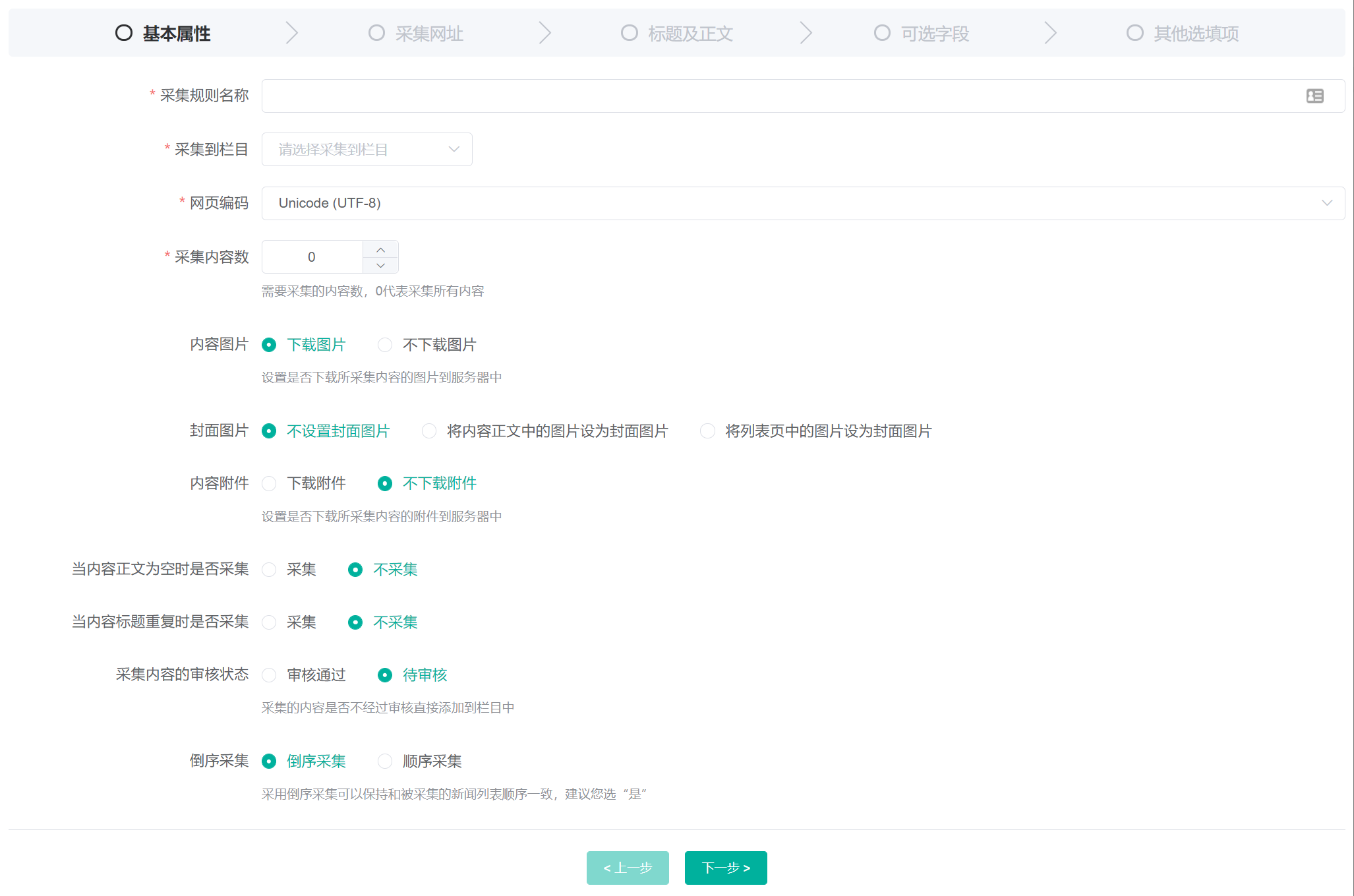
# 采集规则名称
可以取任何您觉得易记的名称,建议使用目标源的名字及域名以便于日后管理。
# 采集到栏目
选择需要将页面数据采集到具体那个栏目。
# 网页编码
必须和采集网站的编码一致,默认是Unicode (UTF-8)。
如果不确定目标网站的网页编码,可以在浏览器中右键列表页,选择 查看页面源代码,在源代码中找到以下标签,其中 charset 对应的值就是页面的网页编码:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
# 采集内容数
表示需要采集的内容数,默认为0,代表采集全部内容。
# 内容图片
内容图片只指文字正文中包含的图片,在此设置是否下载采集内容中的图片到自己的服务器,以防对方网站的图片地址无法访问。
# 封面图片
封面图片是只内容的标题图片(对应内容表的ImageUrl字段),在此设置是否采集封面图片以及封面图片的来源。
不设置封面图片不采集封面图片并将封面图片设置为空值;将内容正文中的图片设为封面图片采集封面图片并从内容正文中获取数据;将列表页中的图片设为封面图片采集封面图片并从列表页中获取数据;
# 内容附件
设置是否下载所采集内容的附件到服务器中,由于附件通常较大,将影响采集速度,默认设置是不下载附件。
如果采集后需要将附件显示在页面中,可以设置为下载附件,以防对方网站的附件地址无法访问。
# 当内容正文为空时是否采集
设置为否采集无内容正文或者采集规则无法获取到正文的页面,默认为不采集。
# 当内容标题重复时是否采集
设置当采集内容的标题在采集的栏目中已存在是是否依旧采集,默认不采集。
# 采集内容的审核状态
采集的内容是否不经过审核直接添加到栏目中,默认设置是未审核。
如果确定采集的数据可以直接显示到网站中,可以设置为审核通过。
# 倒序采集
设置为 倒序采集 可以确保采集的信息顺序和被采集的列表页顺序一致。