# 一、建立采集规则
这里要给大家做示例的网站是国务院网站里面的 要闻频道 ,这是个比较通用和实用的规则。
点击系统左侧- 站点插件 下的 信息采集 右侧进入界面是采集规则管理。然后点击添加信息采集
# 1、采集规则基本信息
TIP
基本信息包括采集规则的名称、以及其他的采集参数设置,如下图:
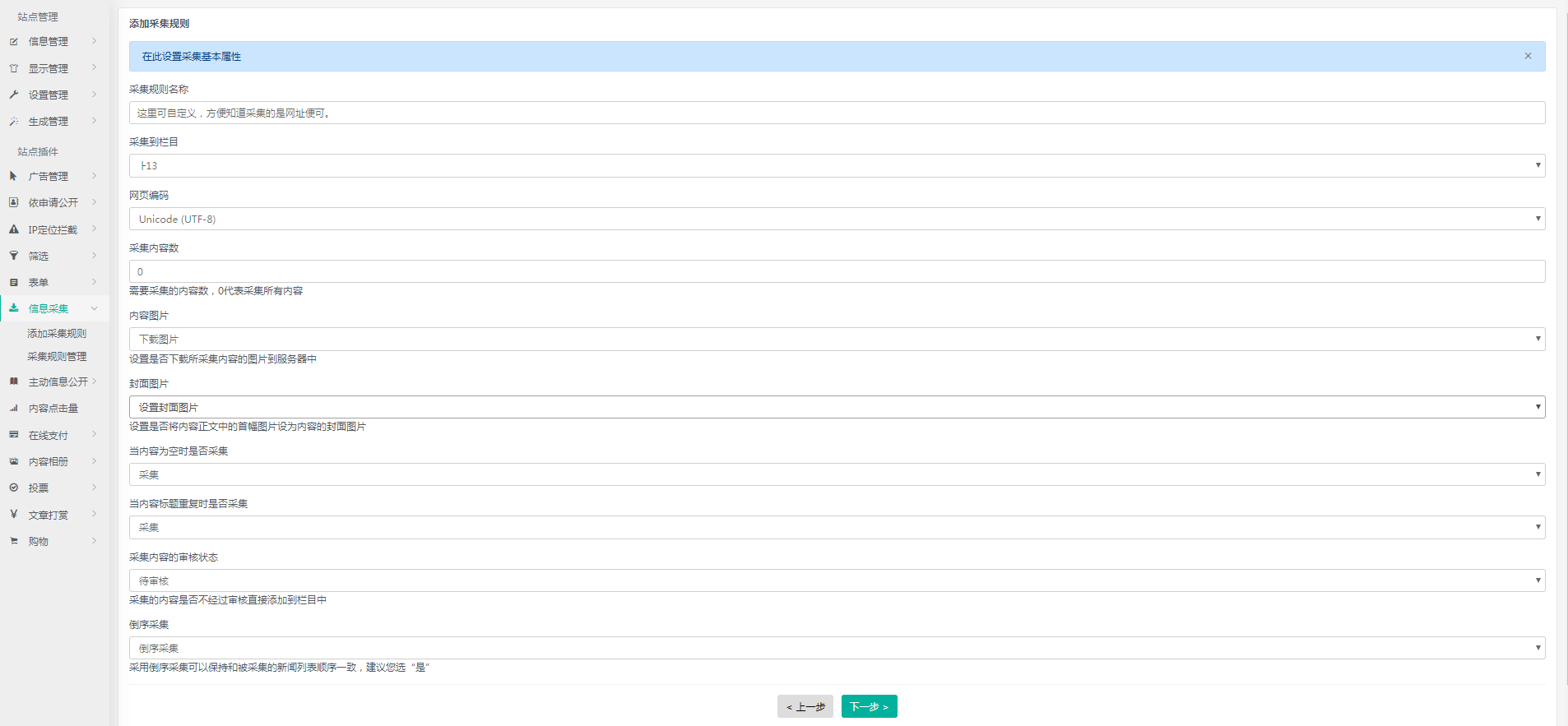
采集规则名称 可以取任何您觉得易记的名称,建议使用目标源的名字及域名以便于日后管理。
采集到栏目 选择采集到具体那个栏目。
网页编码必须和采集网站的编码一致,默认是Unicode (UTF-8)。
采集内容数表示需要采集的条数,默认为0,代表采集全部内容。
内容图片 默认是下载图片项 为确定是否下载采集内容中的图片到自己的服务器,以防对方网站的图片地址无法访问。
封面图片 默认是设置封面图片 设置是否将内容正文中的首幅图片设为内容的封面图片
当内容为空时是否采集 默认设置是 采集
当内容标题重复时是否采集 默认设置是 采集
采集内容的审核状态 默认设置是未审核 采集的内容是否不经过审核直接添加到栏目中
倒序采集 默认设置是倒序采集 采用倒序采集可以保持和被采集的新闻列表顺序一致,建议您选“倒序采集”
# 2、采集内容列表信息
TIP
列表信息包括采集列表的地址以及采集内容地址必须包含的字符串等信息,用于获取采集内容的地址集合,如下图:
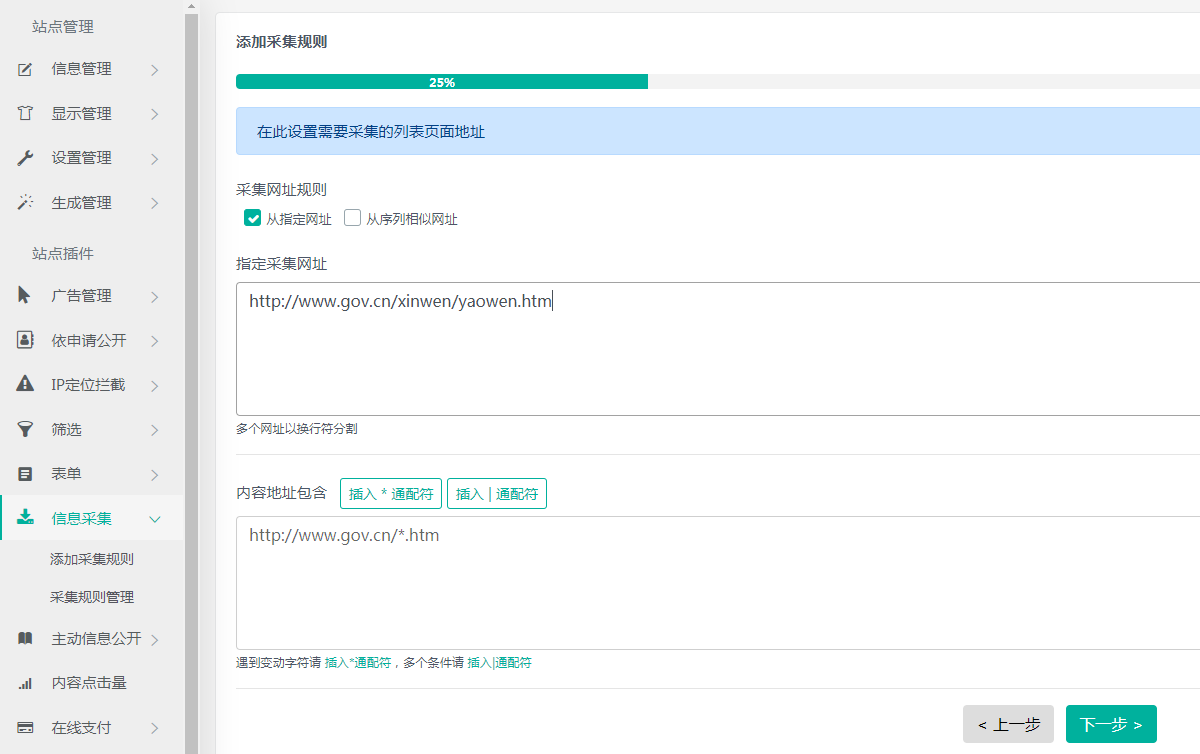
以国务院要闻频道为例,指定采集网址“http://www.gov.cn/xinwen/yaowen.htm”。
由于国务院要闻频道没有翻页,采集网址规则只需勾选“从指定网址”,如果有翻页还需勾选“从序列相似网址”并填入翻页数目。
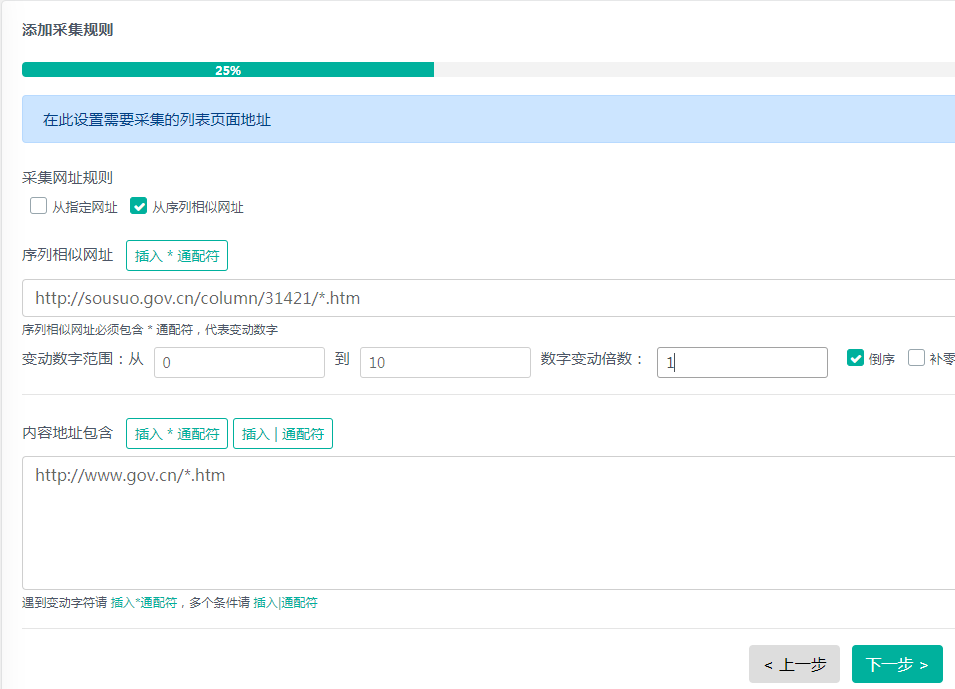
内容地址包含 用于过滤采集的内容地址,系统将从列表页中选择指定格式的地址作为内容页面的链接。如上图所示,系统仅采集包含http://www.gov.cn/*.htm字符串的内容页面,其中*代表任意字符。
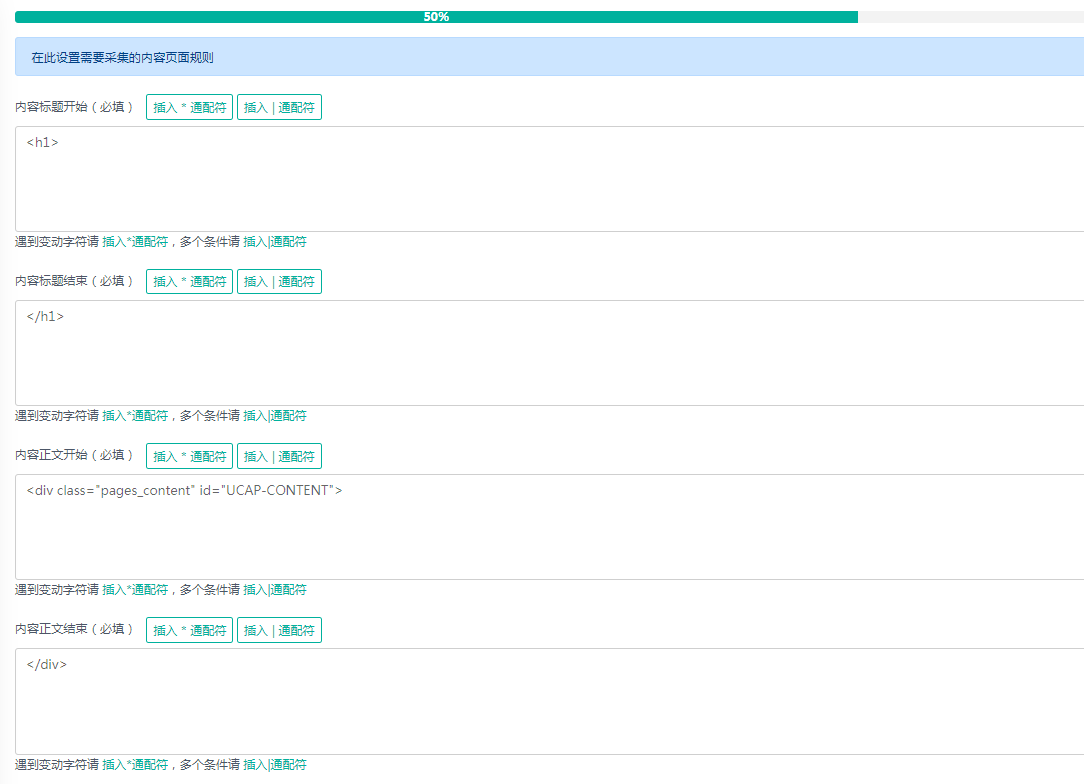
# 3、采集内容页面信息
内容页面信息包括需要采集的页面的信息,包括标题、内容、作者等,如下图:
以国务院要闻频道为例,首先进入内容页面,在浏览器中选择“查看源文件”获取到内容页面的代码。
在代码中找到内容标题,然后找到标题前面和后面的代码,拷贝到内容标题开始以及内容标题结束项中。
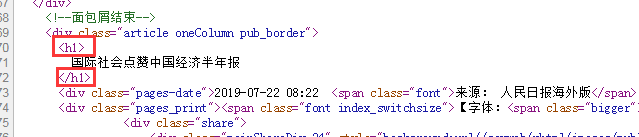
内容正文、内容栏目、内容翻页等元素与内容标题相同,找到对应代码后摘录代码之前及之后的一段代码并填入对应项中。

除默认的内容标题、正文外其他字段同样能够采集,其他需要采集的字段中选择对应的字段即可。
需要注意的是内容正文排除和内容Html清除,这两项能够从内容正文中过滤不需要的信息,如广告等。
选填项 是可以不填写的,除非必要。
接着点击下一步便完成了信息采集规则的添加工作。
添加完成信息采集规则后接下来需要测试此规则能否正常工作。